Pada posting kali ini akan dibuat sebuah program yang dapat mengenali tulisan tangan berupa angka dari 0 sampai 9. Pada proses pembuatan program akan memanfaatkan Python sebagai bahasa pemrograman beserta beberapa library pendukung yang dapat memudahkan jalannya pembuatan sistem. Untuk sistem deteksi dan klasifikasi dari objek angka akan menggunakan algoritma Histogram of Oriented Gradient (HOG) dengan masukan gambar yang berupa tulisan tangan angka dari manusia. Pada pembuatan program ini juga dibutuhkan sekumpulan dataset. Dataset yang digunakan untuk tugas ini adalah dataset MNIST digit recognition yang didapat dari Kaggle.
Teori HOG
Histogram Of Oriented Gradients (HOG) adalah salah satu metode pengekstraksian feature dalam pengolahan citra digital. Metode HOG pertama kali diusulkan oleh Dallal dan Triggs pada tahun 2005 silam dalam studi kasus pendeteksian manusia (person detection). Oleh sebab itu, metode ini sangat cocok untuk digunakan sebagai metode pendeteksian objek lainnya. Akan tetapi, projek ini hanya menggunakan HOG sebagai ekstraksi feature saja. Nilai HOG tersebut akan menjadi masukkan bagi algoritma Support Vector Machine (SVM).
Dalam studi kasus pengenalan karakter ini, metode HOG memanfaatkan penghitungan nilai gradien dari setiap piksel. Nilai gradien tersebut kemudian diolah lebih lanjut dan pada akhirnya akan berfungsi sebagai feature bagi algoritma discriminator, yaitu SVM. Algoritma discriminator inilah yang melakukan prediksi pengenalan karakter.
Langkah-langkah umum HOG dalam melakukan penghitungan gradien pada studi kasus pengenalan karakter adalah sebagai berikut.
- Menghitung nilai gradien dari setiap piksel
Metode ini membutuhkan parameter ukuran cell yang ingin digunakan. Nilai gradien akan dihitung pada masing-masing cell tersebut. Proses penghitungan ini dilakukan secara horizontal dan vertical. Selain itu, dilakukan pula proses penghitungan sudut gradien berdasarkan nilai gradien yang didapatkan. - Masukkan nilai gradient pada histogram
Nilai gradien pada masing-masing cell tersebut kemudian dimasukkan ke dalam histogram. Histogram ini memiliki jumlah batang atau bin yang dapat ditentukan sebelumnya. Melalui proses ini, setiap cell merepresentasikan sebuah histogram yang berisi nilai dan sudut gradien pada masing-masing piksel. Proses ini juga disebut sebagai spatial orientation binning. - Melakukan normalisasi
Histogram-histogram yang didapatkan perlu dilakukan proses normalisasi. Proses ini membutuhkan parameter ukuran block. Pada umumnya, block ini berisi 2×2 cell, 3×3 cell, atau 4×4 cell. Normalisasi ini bertujuan untuk mengecilkan ukuran histogram pada setiap citra karakter. Proses normalisasi block ini menggunakan perhitungan geometri R-HOG.
Teori Kontor (Contour)
Kontur adalah keadaan yang ditimbulkan oleh perubahan intensitas pada pixel-pixel yang bertetangga. Karena adanya perubahan intensitas inilah, maka tepi-tepi (edge) objek pada citra dapat dideteksi. Pendeteksian kontur pada umumnya dilakukan dengan cara melakukan thresholding dan pendeteksian tepi object terlebih dahulu (edge detection). Melalui edge detection ini, proses pemcarian piksel-piksel bertetangga yang terhubung dapat dilakukan.
OpenCV menyediakan sebuah fungsi untuk mencari kontur di dalam citra. Fungsi tersebut bernama “findContours” yang menerima beberapa parameter penting, yaitu citra yang ingin dicari konturnya, mode pengembalian nilai kontur, dan metode pendeteksian kontur.
Library Yang Dibutuhkan:
- Scikit-learn
Scikit-learn merupakan library yang digunakan dalam pengolahan machine learning melalui Python. Scikit-learn memungkinan kita dalam melakukan beragam pekerjaan untuk Data Science, seperti melakukan regresi (regression), klarifikasi (classification), pengelompokan (clustering), data preprocessing, dimensionality reduction, dan model selection (pembandingan, validasi, dan pemilihan parameter atau model). Untuk menginstallnya dapat melalui cmd dengan menuliskan pip install scikit-learn. - Scikit-image
Scikit-image merupakan library yang disediakan oleh python untuk image processing. Untuk menginstallnya dapat melalui cmd dengan menuliskan pip install scikit-image. - Mahotas
Mahotas merupakan computer vision dan image processing untuk Python. Mahotas mencakup banyak algortima yang diimplementasikan dalam C++ untuk kecepatan beroperasi di array numpy dan antarmuka Python yang bersih.Mahotas memiliki lebih dari 100 fungsi untuk image processing dan computer vision dan terus berkembang sampai sekarang. Fungsi mahotas meliputi :
– Watershed
– Conves points calculations
– Hit, miss, thining
– Morphological processing
– Thresholding
– Convolution
– Sobel edge detection
– Local binary patterns - OpenCV
OpenCV merupakan libaty yang digunakan untuk mengolah gambar dan video untuk dapat meng-ekstrak informasi didalamnya. OpenCV dapat berjalan di berbagai bahasa pemrograman seperti C, C++, Java, Python. Contoh dalam penggunana OpenCV adalah bagaimana kita mendeteksi wajah dalam sebuah gambar. - NumPy
Numpy merupakan modul untuk komputasi ilmiah dalam Python. NumPy berisi tenyang :
– Objek N-Dimensional Array
– Broadcasting yang cepat
– Tools yang terintegrasi dengan C/C++ dan Fortran
– Fungsi aljabar linear, fourier transform dan kemampuan pengolahan angka. - Imutils
Imutils merupakan library untuk melakukan translation, rotation, resizing, and skeletonization.
Dataset untuk Pengenalan Tulisan Tangan Angka
Dataset yang digunakan dalam proyek ini diambil dari web Kaggle.com. Data tersebut berbentuk .csv yang terdiri dari 42.000 data. Detail dari file csv tersebut adalah kolom pertama merupakan label dan kolom kedua dan seterusnya merupakan intensitas.
Dataset tersebut jika direpresentasikan maka akan menghasilkan gambar berupa tulisan angka seperti pada gambar di bawah ini:

Langkah-langkah pembuatan aplikasi:
Pembuatan hog.py
Berisi class HOG yang berfungsi sebagai definisi bagi algoritma HOG.
- Import library yang digunakan
from skimage import feature
Class HOG membutuhkan library “feature” milik package “skimage”. Dengan memanfaatkan library yang telah disediakan tersebut, proses pembuatan algoritma HOG tidak perlu dilakukan mulai dari awal.
- Pendefinisian constructor
def __init__(self, orientations=9, pixelsPerCell=(8,8), cellsPerBlock=(3,3), transform=False): self.orientations = orientations self.pixelsPerCell = pixelsPerCell self.cellsPerBlock = cellsPerBlock self.transform = transform
Pembuatan constructor bertujuan untuk mendefinisikan variabel-variabel penting pada algoritma HOG. Variabel-variabel tersebut yaitu jumlah orientation, dimensi cell, jumlah cell pada tiap block, dan penggunaan square root dalam penghitungan HOG.
- Fungsi untuk penghitungan HOG pada citra
def describe(self, image): hist = feature.hog(image, orientations = self.orientations, pixels_per_cell = self.pixelsPerCell, cells_per_block = self.cellsPerBlock, transform_sqrt = self.transform) return hist
Fungsi ini bertujuan untuk memulai proses pengambilan feature HOG pada citra yang dimasukkan sebagai parameter. Feature yang dihasilkan kemudian dimasukkan ke dalam variabel “hist” dan dikembalikan kepada pemanggil fungsi.
Pembuatan file dataset.py
Berkas ini berisi tiga buah fungsi yang bertujuan sebagai langkah preprocessing citra sebelum dilakukan proses training SVM.
- Import library yang digunakan
import imutils import numpy as np import mahotas import cv2
Library “imutils” berfungsi untuk melakukan proses scaling pada fungsi “center_extent”. Library “numpy” digunakan dalam proses pengambilan dataset dari berkas csv, proses penghitungan moment pada fungsi “deskew”, dan pembuatan array baru pada fungsi “center_extent”. Sementara itu, library “mahotas” merupakan library penting dalam proses penengahan karakter dalam citra. Terakhir, library cv2 atau OpenCV adalah library pengolahan citra digital yang berperan penting dalam keseluruhan aplikasi.
- Pembuatan fungsi “load_digits”
Secara umum fungsi ini bertujuan untuk mengambil dataset yang tersimpan dalam berkas csv.
def load_digits(datasetPath): data = np.genfromtxt(datasetPath, delimiter=",",dtype="uint8") target = data[:, 0] data = data[:, 1:].reshape(data.shape[0], 28,28) return (data, target)
Fungsi “load_digits” menerima sebuah parameter yaitu “datasetPath”. Variabel tersebut menunjukkan path dari dataset yang berupa berkas csv. Proses pembacaan berkas csv tersebut dilakukan dengan menggunakan fungsi “genfromtxt” milik library “numpy”. Setelah itu, dilakukan proses pemecahan array untuk mengambil data latih dan data target berdasarkan data pada berkas csv. Data target tersebut disimpan dalam variabel “target” sedangkan data latih disimpan dalam variabel “data”. Untuk data latih, dilakukan proses pengubahan dimensi array (reshape) terlebih dahulu supaya data latih tersebut berdimensi 28×28 piksel. Proses reshape ini juga bertujuan agar data latih dapat dibaca oleh OpenCV sebagai citra. Data latih dan data target tersebut kemudian dikembalikan kepada perintah pemanggil.
- Pembuatan fungsi “deskew”
Fungsi “deskew” bertujuan untuk mencegah data citra karakter condong ke kanan atau ke kiri.
def deskew(image, width): (h, w) = image.shape[:2] moments = cv2.moments(image) skew = moments["mu11"] / moments["mu02"] M = np.float32([ [1, skew, -0.5 * w * skew], [0, 1, 0] ]) image = cv2.warpAffine(image, M, (w, h), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR) image = imutils.resize(image, width=width) return image
Langkah pertama yaitu menghitung moment citra masukkan. Moment ini berisi informasi statistik persebaran piksel terang pada citra. Tingkat kemiringan citra kemudian dihitung berdasarkan moment tersebut. Setelah itu, proses deskew atau penegakkan karakter dilakukan dengan menggunakan fungsi “warpAffine” milik library OpenCV. Karakter yang telah diproses kemudian dilakukan scaling berdasarkan ukuran “width” pada parameter fungsi.
- Pembuatan fungsi “center_extent”
Fungsi ini bertujuan untuk memposisikan karakter agar berada tepat di tengah citra dan memastikan citra memiliki ukuran panjang atau lebar yang sama (persegi).
def center_extent(image, size):
(eW, eH) = size
if(image.shape[1] > image.shape[0]):
image = imutils.resize(image, width=eW)
else:
image = imutils.resize(image, height=eH)
extent = np.zeros((eH, eW), dtype="uint8")
offsetX = (eW - image.shape[1]) // 2
offsetY = (eH - image.shape[0]) // 2
extent[offsetY:offsetY + image.shape[0],
offsetX:offsetX + image.shape[1]] = image
CM = mahotas.center_of_mass(extent)
(cY, cX) = np.round(CM).astype("int32")
(dX, dY) = ((size[0] // 2) - cX, (size[1] // 2) - cY)
M = np.float32([[1,0,dX], [0,1,dY]])
extent = cv2.warpAffine(extent, M, size)
return extent
Proses ini dimulai dengan melakukan pengecekan ukuran citra masukkan terlebih dahulu. Apabila lebar citra lebih besar daripada tinggi citra, maka dilakukan scaling berdasarkan lebar citra, begitu pula sebaliknya. Setelah itu, dilakukan pembuatan citra baru berwarna hitam bernama “extent” dengan memanfaatkan fungsi milik “numpy”. Kemudian dilakukan penghitungan “offsetX” dan “offsetY” untuk menentukan dimana posisi karakter akan diletakkan di dalam “extent”. Terakhir, dilakukan proses pergeseran karakter agar tepat berada di tengah. Proses ini menggunakan fungsi “center_of_mass” milik library “mahotas”.
Pembuatan file train.py
Berkas train.py berisi langkah-langkah pelatihan algoritma SVM berdasarkan feature HOG. Poin-poin berikut ini menjelaskan langkah pelatihan dalam berkas tersebut.
- Import library yang dibutuhkan
from sklearn.externals import joblib from sklearn.svm import LinearSVC from hog import HOG import dataset
Penjelasan mengenai library-library tersebut adalah sebagai berikut.
- Kelas “joblib” berfungsi untuk menyimpan model SVM yang telah dilatih.
- “LinearSVC” merupakan kelas untuk mendefinisikan algoritma SVM. Kelas tersebut telah disediakan oleh library “scikit-learn”.
- Kelas “HOG” berfungsi untuk mendefinisikan algoritma HOG. Kelas ini telah dibuat pada langkah sebelumnya.
- “dataset” merupakan berkas yang telah dibuat pada langkah sebelumnya. Berkas ini berisi fungsi yang berguna untuk melakukan preprocessing
- Pengambilan dataset dan pendefinisian HOG
(digits, target) = dataset.load_digits('dataset/train.csv')
data = []
hog = HOG(orientations=18, pixelsPerCell=(10,10),
cellsPerBlock=(1,1), transform=True)
Proses pelatihan dimulai dengan mengambil dataset yang tersimpan di dalam berkas csv. Oleh sebab itu, dilakukan pemanggilan fungsi “load_digits” yang terletak pada berkas “dataset”. Pemanggilan fungsi tersebut disertai dengan lokasi penyimpanan berkas csv yaitu “dataset/train.csv”. Fungsi “load_digits” mengembalikan dua buah nilai. Nilai pertama berisi data citra latih sedangkan nilai kedua berisi data target.
Proses pelatihan kemudian dilanjutkan dengan mendefinisikan kelas HOG yang telah dibuat sebelumnya. Parameter yang dimasukkan diantaranya adalah “orientations” berjumlah 18 buah, “pixelsPerCell” berdimensi 10×10, “cellsPerBlock” berukuran 1×1, dan “transform” yang bernilai True.
- Penghitungan HOG
for image in digits: image = dataset.deskew(image, 20) image = dataset.center_extent(image, (20,20)) hist = hog.describe(image) data.append(hist)
Pada langkah ini, dilakukan preprocessing dan ekstraksi feature terhadap setiap citra latih sebelum proses pelatihan SVM dimulai. Preprocessing ini memanfaatkan dua fungsi pada berkas “dataset.py” yang telah dibuat sebelumnya, yaitu fungsi “deskew” dan “center_extent”. Masing-masing fungsi tersebut membutuhkan parameter berupa citra yang ingin diproses dan ukuran citra yang diinginkan. Citra yang telah diproses tersebut lalu dihitung nilai HOG-nya menggunakan fungsi “describe” milik kelas “HOG”. Feature yang berhasil didapatkan kemudian disimpan dalam variabel “hist”, dan variabel “hist” tersebut lalu dimasukkan kembali ke dalam array “data”.
- Pelatihan SVM
model = LinearSVC(random_state=42) model.fit(data, target) joblib.dump(model, 'model/svm.cpickle')
Setelah feature HOG pada setiap citra latih telah didapatkan, maka dilakukan proses pelatihan menggunakan algoritma SVM. Proses pelatihan ini menggunakan kelas ”LinearSVC” milik library “scikit-learn” yang didefinisikan sebagai variabel “model”. Melalui variabel “model” tersebut, maka proses pelatihan SVM dimulai dengan memanggil fungsi “fit” yang membutuhkan dua parameter, yaitu data latih dan data target. Model yang telah dilatih kemudian disimpan ke dalam hardisk menggunakan fungsi “dump” milik kelas “joblib”.
- Pembuatan berkas classify.py
Berkas ini berisi baris perintah untuk mendeteksi karakter di dalam citra uji sekaligus melakukan pengenalan pada karakter tersebut. Langkah-langkah pendeteksian karakter adalah sebagai berikut.
- Import library yang dibutuhkan
from sklearn.externals import joblib from hog import HOG import dataset import mahotas import cv2
Penjelasan terkait dengan library yang digunakan adalah sebagai berikut.
- “joblib” berfungsi untuk mengambil model yang disimpan dalam hardisk
- “HOG” berfungsi untuk mendefinisikan algoritma HOG
- “dataset” berfungsi untuk melakukan preprocessing pada citra
- “mahotas” berfungsi untuk melakukan thresholding
- “cv2” berfungsi untuk melakukan pengolahan citra
- Ambil model dan pendefinisian HOG
model = joblib.load('model/svm.cpickle')
hog = HOG(orientations=18, pixelsPerCell=(10,10),
cellsPerBlock=(1,1), transform=True)
Pada langkah ini dilakukan pengambilan model SVM yang telah dilatih menggunakan fungsi “load” milik “joblib”. Setelah itu, dilakukan pendefinisian HOG berdasarkan parameter-parameter yang ditentukan.
- Preprocessing citra
image = cv2.imread('image/tes3.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5,5), 0)
edged = cv2.Canny(blurred, 30, 150)
(_, cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = sorted([(c, cv2.boundingRect(c)[0]) for c in cnts],
key=lambda x:x[1])
Langkah ini dimulai dengan membaca citra yang ingin dilakukan pengenalan karakter. Setelah itu, citra yang telah dibaca diubah ke dalam mode grayscale untuk dilakukan proses gaussian blur. Kemudian diterapkan metode edge detection menggunakan metode Canny. Hasil edge detection ini merupakan dasar untuk pencarian kontur di dalam citra. Pencarian kontur ini menggunakan fungsi “findContour” milik library “cv2”. Kontur yang berhasil didapatkan kemudian diurutkan dari kiri ke kanan untuk memudahkan proses evaluasi.
- Preprocessing pada setiap kontur
for (c, _) in cnts:
(x,y,w,h) = cv2.boundingRect(c)
if(w >= 7 and h >= 20):
roi = gray[y:y+h, x:x+w]
thresh = roi.copy()
cv2.imshow("ori", thresh)
T = mahotas.thresholding.otsu(roi)
thresh[thresh > T] = 255
thresh = cv2.bitwise_not(thresh)
thresh = dataset.deskew(thresh, 20)
thresh = dataset.center_extent(thresh, (20,20))
Pada tahap ini dilakukan perulangan untuk memberikan bounding box di area sekitar kontur. Setelah itu dilakukan pengecekan kondisi apakah lebar dan tinggi bounding box melebihi batas yang telah ditentukan. Apabila memiliki lebar dan tinggi yang melebihi batas, maka kontur tersebut akan dianggap sebagai citra karakter, namun jika sebaliknya, maka kontur tersebut dianggap sebagai noise sehingga tidak dilakukan proses pengenalan karakter. Kemudian dilakukan proses thresholding pada kontur yang dianggap sebagai karakter. Karena dataset yang digunakan adalah citra berlatar belakang hitam dengan tulisan putih, maka perlu untuk dilakukan proses invert pada citra threshold. Selanjutnya dilakukan proses deskew dan center extent pada masing-masing kontur untuk menyamakan kondisi setiap kontur dengan citra dataset.
- Pengenalan karakter
hist = hog.describe(thresh)
digit = model.predict([hist])[0]
cv2.rectangle(image, (x,y), (x+w, y+h), (0,255,0),1)
cv2.putText(image, str(digit), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0,255,0),2)
cv2.imshow("image", image)
cv2.waitKey(0)
Masing-masing kontur yang telah diproses kemudian dihitung feature HOG-nya menggunakan fungsi “describe”. Setelah itu dilakukan proses pengenalan karakter berdasarkan feature HOG yang telah didapatkan tersebut. Nilai prediksi disimpan ke dalam variabel “digit” dan dicetak ke dalam citra masukkan. Terakhir, citra masukkan dan hasil prediksi tersebut ditampilkan ke layar dengan memanfaatkan fungsi “imshow”.
PENGUJIAN YANG DILAKUKAN
Pengujian dilakukan pada program yang telah dibuat dengan menggunakan beberapa gambar dari tulisan tangan yang berupa sekumpulan angka, gambar tersebut akan menjadi nilai masukan pada program. Pada data uji yang pertama kami menggunakan sebuah gambar yang berisikan angka dari 1 sampai angka 9. Berikut adalah gambar yang digunakan untuk data uji yang pertama.

Pada data uji yang pertama didapatkan akurasi 88% dimana semua angka pada gambar berhasil diklasifikasikan secara benar kecuali angka 9. Pada angka 9 diklasifikasikan sebagai angka 4 oleh sistem. Kesalahan seperti ini dapat terjadi dikarenakan pada data latih angka 9 dan angka 4 memiliki bentuk yang mirip. Hal lain yang dapat menyebabkan kesalahan ini adalah pada proses preprocessing yang mengakibatkan bentuk awal dari suatu angka menjadi berubah. Berikut adalah hasil dari klasifikasi pada data uji yang pertama.

Kemudian pada data uji yang kedua dicoba untuk menggunakan gambar yang tidak memiliki angka 9. Untuk mencari tahu apakah angka yang lain dapat diklasifikasikan dengan baik oleh sistem. Pada gambar data uji yang kedua ini berisikan angka acak antara 1 sampai 8. Berikut adalah gambar yang digunakan.
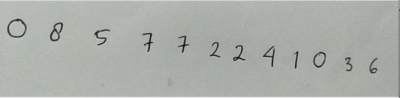
Pada data uji yang kedua ini terdapat 12 angka acak yang berhasil diklasifikasikan oleh sistem dengan mendapatkan akurasi 100%. Dimana semua angka pada gambar dapat diklasifikasikan dengan benar oleh sistem. Hal ini membuktikan bahwa data latih pada angka 1 sampai 8 memiliki tingkat kesamaan yang minimum dan perubahan bentuk pada saat preprocessing tidak membuat angka 1 sampai 8 memiliki perubahan yang signifikan. Berikut adalah hasil dari klasifikasi pada data uji yang kedua.
